
E20-065 Online Practice Questions and Answers
Questions 4
Given an input vector of features, a Random Forests model performs a classification task and ends in a tie. How does the model handle this outcome?
A. The model will be rebuilt
B. A winner is chosen at random
C. The tree that caused the tie is discarded
D. One more tree is added to the forest
Questions 5
Why would a company decide to use HBase to replace an existing relational database?
A. It is required for performing ad-hoc queries.
B. Varying formats of input data requires columns to be added in real time.
C. The company's employees are already fluent in SQL.
D. Existing SQL code will run unchanged on HBase.
Questions 6
What is an ideal use case for HDFS?
A. Storing files that are updated frequently
B. Storing files that are written once and read many times
C. Storing results between Map steps and Reduce steps
D. Storing application files in memory
Questions 7
A marketing team creates a graph using a square for each data point, where the length of each side is set to the data value. The data values are 10 and 20.
What is the lie factor of the graph?
A. 1
B. 2
C. 3
D. 6
Questions 8
How does Latent Dinchlet Allocation (LDA) interpret a document?
A. As a single-predefined topic
B. As a mixture of pre-defined topics
C. As having a mixture of sentiments
D. As having a single pre-defined sentiment
Questions 9
What is an important simu-lation design consideration?
A. Ensure model Inputs align with reality
B. Use different seed values to regenerate results
C. For rare event models, minimize number of trials
D. A complex model is better than a simple model
Questions 10
Assuming the node index starts at 1, what is the out-degree of node 3 in the adjacency matrix shown? Refer to the exhibit.
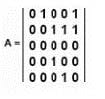
A. 0
B. 1
C. 2
D. 3
Questions 11
What is a random subspace of features, as used by Random Forests?
A. A random subset of features that are chosen at each split in the decision tree
B. Filtration of data that does not meet a pre-defined weighting thrsehold
C. The creation of out-of-bag (OOB) data that is used to select features
D. Removal of highly correlated variables to randomize the features
Questions 12
In the graph, which edge would be considered a weak lie? Refer to the exhibit.
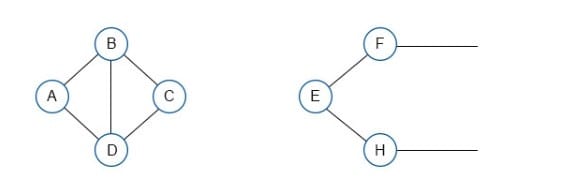
A. C-E
B. E-F
C. B-C
D. G-l
Questions 13
What do first-order and second-order Markov processes have in common concerning next word prediction?
A. Both use WordNet to model the probability of the next word
B. Both are unsupervised methods
C. Both provide the foundation to build a trigram language model
D. Neither makes assumptions about the probability of the next word
![]()
![]()
Home | About Us | Contact Us | FAQ | Guarantee Policy | Privacy Policy
Any charges made through this site will appear as Global Simulators Limited. All trademarks are the property of their respective owners.
Copyright © 2004-2025 pass2lead.com, All Rights Reserved.