
DP-100 Online Practice Questions and Answers
Questions 4
DRAG DROP
You configure a Deep Learning Virtual Machine for Windows.
You need to recommend tools and frameworks to perform the following:
1.
Build deep neural network (DNN) models
2.
Perform interactive data exploration and visualization
Which tools and frameworks should you recommend? To answer, drag the appropriate tools to the correct tasks. Each tool may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view
content.
NOTE: Each correct selection is worth one point.
Select and Place:


Questions 5
DRAG DROP
You create a multi-class image classification deep learning experiment by using the PyTorch framework. You plan to run the experiment on an Azure Compute cluster that has nodes with GPU's.
You need to define an Azure Machine Learning service pipeline to perform the monthly retraining of the image classification model. The pipeline must run with minimal cost and minimize the time required to train the model.
Which three pipeline steps should you run in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
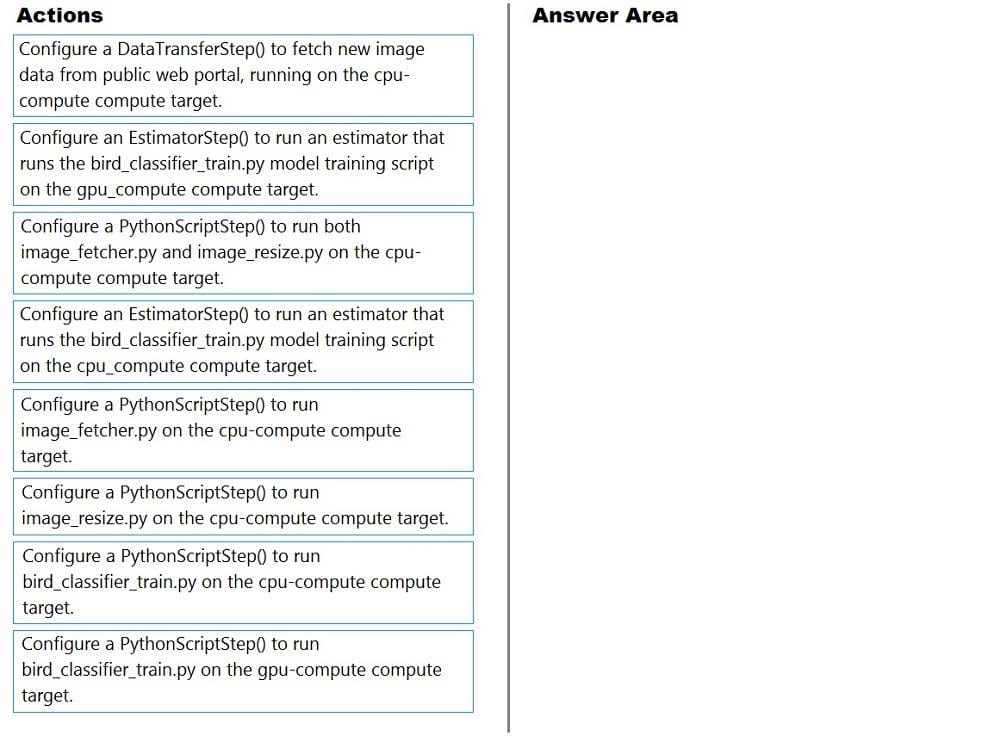
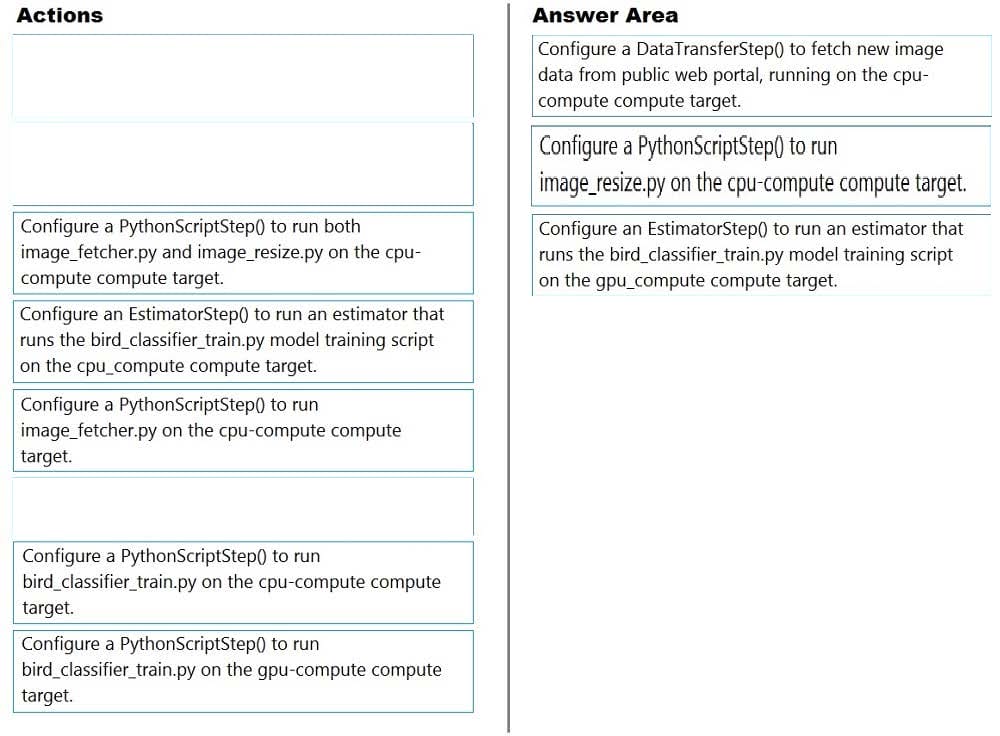
Questions 6
You have a dataset created for multiclass classification tasks that contains a normalized numerical feature set with 10,000 data points and 150 features.
You use 75 percent of the data points for training and 25 percent for testing. You are using the scikit-learn machine learning library in Python. You use X to denote the feature set and Y to denote class labels.
You create the following Python data frames:
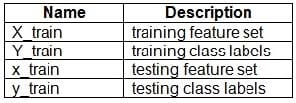
You need to apply the Principal Component Analysis (PCA) method to reduce the dimensionality of the feature set to 10 features in both training and testing sets. How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

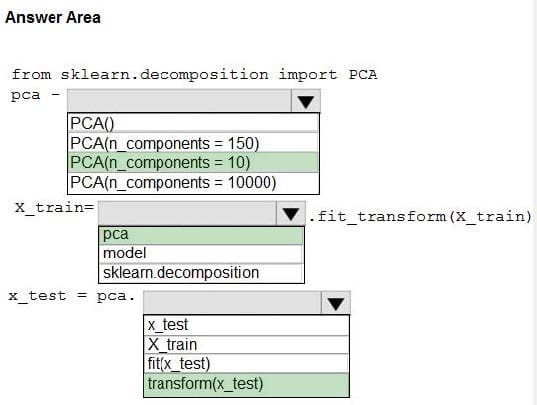
Questions 7
HOTSPOT
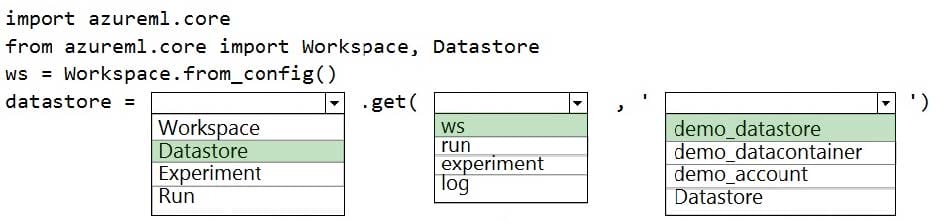
A coworker registers a datastore in a Machine Learning services workspace by using the following code:

You need to write code to access the datastore from a notebook.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Questions 8
HOTSPOT
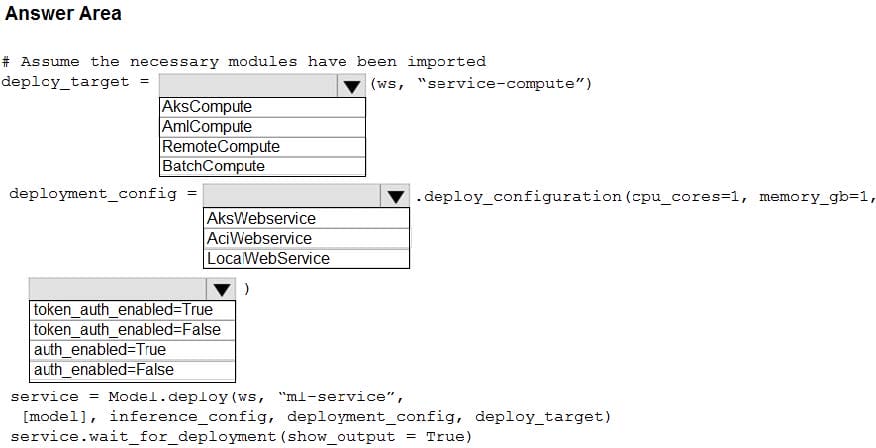
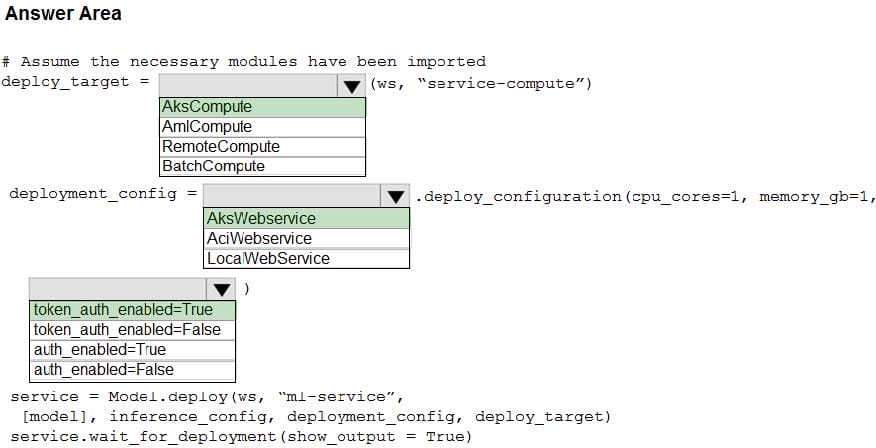
You use Azure Machine Learning to train and register a model.
You must deploy the model into production as a real-time web service to an inference cluster named service-compute that the IT department has created in the Azure Machine Learning workspace.
Client applications consuming the deployed web service must be authenticated based on their Azure Active Directory service principal.
You need to write a script that uses the Azure Machine Learning SDK to deploy the model. The necessary modules have been imported.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Questions 9
You plan to run a Python script as an Azure Machine Learning experiment. The script contains the following code:
import os, argparse, globfrom azureml.core import Run
parser = argparse.ArgumentParser()parser.add_argument('--input-data',
type=str, dest='data_folder')args = parser.parse_args()data_path = args.data_folderfile_paths = glob.glob(data_path + "/*.jpg")
You must specify a file dataset as an input to the script. The dataset consists of multiple large image files and must be streamed directly from its source.
You need to write code to define a ScriptRunConfigobject for the experiment and pass the ds dataset as an argument.
Which code segment should you use?
A. arguments = ['--input-data', ds.to_pandas_dataframe()]
B. arguments = ['--input-data', ds.as_mount()]
C. arguments = ['--data-data', ds]
D. arguments = ['--input-data', ds.as_download()]
Questions 10
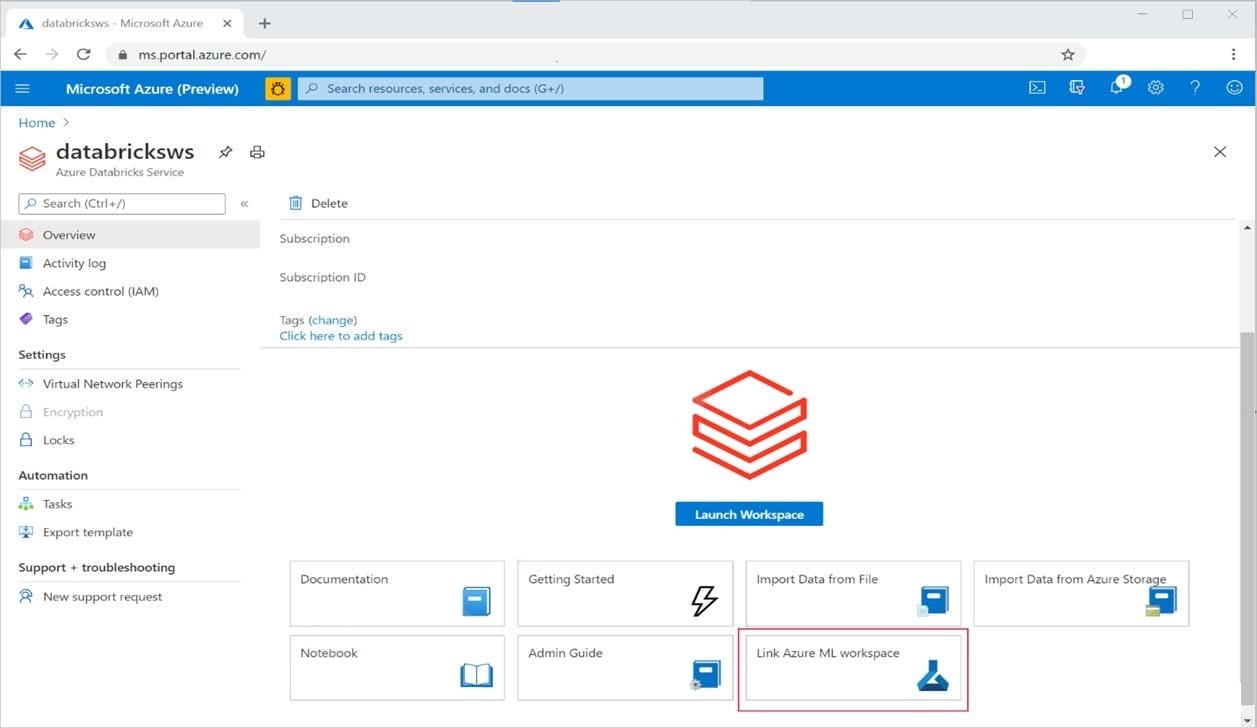
You create an Azure Machine Learning workspace named ML-workspace. You also create an Azure Databricks workspace named DB-workspace. DB-workspace contains a cluster named DB-cluster.
You must use DB-cluster to run experiments from notebooks that you import into DB-workspace.
You need to use ML-workspace to track MLflow metrics and artifacts generated by experiments running on DB-cluster. The solution must minimize the need for custom code.
What should you do?
A. From DB-cluster, configure the Advanced Logging option.
B. From DB-workspace, configure the Link Azure ML workspace option.
C. From ML-workspace, create an attached compute.
D. From ML-workspace, create a compute cluster.
Questions 11
You have been tasked with creating a new Azure pipeline via the Machine Learning designer.
You have to makes sure that the pipeline trains a model using data in a comma-separated values (CSV) file that is published on a website. A dataset for the file for this file does not exist.
Data from the CSV file must be ingested into the designer pipeline with the least amount of administrative effort as possible.
Which of the following actions should you take?
A. You should make use of the Convert to TXT module.
B. You should add the Copy Data object to the pipeline.
C. You should add the Import Data object to the pipeline.
D. You should add the Dataset object to the pipeline.
Questions 12
You are in the process of creating a machine learning model. Your dataset includes rows with null and missing values.
You plan to make use of the Clean Missing Data module in Azure Machine Learning Studio to detect and fix the null and missing values in the dataset.
Recommendation: You make use of the Replace with median option.
Will the requirements be satisfied?
A. Yes
B. No
Questions 13
You create an Azure Machine Learning pipeline named pipeline 1 with two steps that contain Python scripts. Data processed by the first step is passed to the second step.
You must update the content of the downstream data source of pipeline 1 and run the pipeline again.
You need to ensure the new run of pipeline 1 fully processes the updated content.
Solution: Change the value of the compute.target parameter of the PythonScriptStep object in the two steps.
Does the solution meet the goal?
A. Yes
B. No
![]()
![]()
Home | About Us | Contact Us | FAQ | Guarantee Policy | Privacy Policy
Any charges made through this site will appear as Global Simulators Limited. All trademarks are the property of their respective owners.
Copyright © 2004-2025 pass2lead.com, All Rights Reserved.