
CCA-500 Online Practice Questions and Answers
Questions 4
Assuming you're not running HDFS Federation, what is the maximum number of NameNode daemons you should run on your cluster in order to avoid a "split-brain" scenario with your NameNode when running HDFS High Availability (HA) using Quorum-based storage?
A. Two active NameNodes and two Standby NameNodes
B. One active NameNode and one Standby NameNode
C. Two active NameNodes and on Standby NameNode
D. Unlimited. HDFS High Availability (HA) is designed to overcome limitations on the number of NameNodes you can deploy
Questions 5
Cluster Summary:
45 files and directories, 12 blocks = 57 total. Heap size is 15.31 MB/193.38MB(7%)
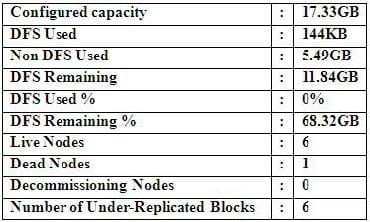
Refer to the above screenshot.
You configure a Hadoop cluster with seven DataNodes and on of your monitoring UIs displays the details
shown in the exhibit.
What does the this tell you?
A. The DataNode JVM on one host is not active
B. Because your under-replicated blocks count matches the Live Nodes, one node is dead, and your DFS Used % equals 0%, you can't be certain that your cluster has all the data you've written it.
C. Your cluster has lost all HDFS data which had bocks stored on the dead DatNode
D. The HDFS cluster is in safe mode
Questions 6
You use the hadoop fs put command to add a file "sales.txt" to HDFS. This file is small enough that it fits into a single block, which is replicated to three nodes in your cluster (with a replication factor of 3). One of the nodes holding this file (a single block) fails. How will the cluster handle the replication of file in this situation?
A. The file will remain under-replicated until the administrator brings that node back online
B. The cluster will re-replicate the file the next time the system administrator reboots the NameNode daemon (as long as the file's replication factor doesn't fall below)
C. This will be immediately re-replicated and all other HDFS operations on the cluster will halt until the cluster's replication values are resorted
D. The file will be re-replicated automatically after the NameNode determines it is under- replicated based on the block reports it receives from the NameNodes
Questions 7
Assume you have a file named foo.txt in your local directory. You issue the following three commands:
Hadoop fs mkdir input
Hadoop fs put foo.txt input/foo.txt
Hadoop fs put foo.txt input
What happens when you issue the third command?
A. The write succeeds, overwriting foo.txt in HDFS with no warning
B. The file is uploaded and stored as a plain file named input
C. You get a warning that foo.txt is being overwritten
D. You get an error message telling you that foo.txt already exists, and asking you if you would like to overwrite it.
E. You get a error message telling you that foo.txt already exists. The file is not written to HDFS
F. You get an error message telling you that input is not a directory
G. The write silently fails
Questions 8
On a cluster running MapReduce v2 (MRv2) on YARN, a MapReduce job is given a directory of 10 plain text files as its input directory. Each file is made up of 3 HDFS blocks. How many Mappers will run?
A. We cannot say; the number of Mappers is determined by the ResourceManager
B. We cannot say; the number of Mappers is determined by the developer
C. 30
D. 3
E. 10
F. We cannot say; the number of mappers is determined by the ApplicationMaster
Questions 9
You are running Hadoop cluster with all monitoring facilities properly configured.
Which scenario will go undeselected?
A. HDFS is almost full
B. The NameNode goes down
C. A DataNode is disconnected from the cluster
D. Map or reduce tasks that are stuck in an infinite loop
E. MapReduce jobs are causing excessive memory swaps
Questions 10
Choose three reasons why should you run the HDFS balancer periodically? (Choose three)
A. To ensure that there is capacity in HDFS for additional data
B. To ensure that all blocks in the cluster are 128MB in size
C. To help HDFS deliver consistent performance under heavy loads
D. To ensure that there is consistent disk utilization across the DataNodes
E. To improve data locality MapReduce
Questions 11
You have just run a MapReduce job to filter user messages to only those of a selected geographical region. The output for this job is in a directory named westUsers, located just below your home directory in HDFS. Which command gathers these into a single file on your local file system?
A. Hadoop fs getmerge R westUsers.txt
B. Hadoop fs getemerge westUsers westUsers.txt
C. Hadoop fs cp westUsers/* westUsers.txt
D. Hadoop fs get westUsers westUsers.txt
Questions 12
In CDH4 and later, which file contains a serialized form of all the directory and files inodes in the filesystem, giving the NameNode a persistent checkpoint of the filesystem metadata?
A. fstime
B. VERSION
C. Fsimage_N (where N reflects transactions up to transaction ID N)
D. Edits_N-M (where N-M transactions between transaction ID N and transaction ID N)
Questions 13
Your Hadoop cluster contains nodes in three racks. You have not configured the dfs.hosts property in the NameNode's configuration file. What results?
A. The NameNode will update the dfs.hosts property to include machines running the DataNode daemon on the next NameNode reboot or with the command dfsadmin refreshNodes
B. No new nodes can be added to the cluster until you specify them in the dfs.hosts file
C. Any machine running the DataNode daemon can immediately join the cluster
D. Presented with a blank dfs.hosts property, the NameNode will permit DataNodes specified in mapred.hosts to join the cluster
![]()
![]()
Home | About Us | Contact Us | FAQ | Guarantee Policy | Privacy Policy
Any charges made through this site will appear as Global Simulators Limited. All trademarks are the property of their respective owners.
Copyright © 2004-2025 pass2lead.com, All Rights Reserved.