
E20-026 Online Practice Questions and Answers
Questions 4
What is an example of a null hypothesis?
A. that a newly created model does not provide better predictions than the currently existing model
B. that a newly created model provides a prediction of a null sample mean
C. that a newly created model provides a prediction of a null population mean
D. that a newly created model provides a prediction that will be well fit to the null distribution
Questions 5
A data scientist wants to predict the probability of death from heart disease based on three risk factors: age, gender, and blood cholesterol level.
What is the most appropriate method for this project?
A. Logistic regression
B. Linear regression
C. K-means clustering
D. Apriori algorithm
Questions 6
In linear regression modeling, which action can be taken to improve the linearity of the relationship between the dependent and independent variables?
A. Apply a transformation to a variable
B. Use a different statistical package
C. Calculate the R-Squared value
D. Change the units of measurement on the independent variable
Questions 7
You have been assigned to do a study of the daily revenue effect of a pricing model of online transactions. All the data currently available to you has been loaded into your analytics database; revenue data, pricing data, and online transaction data. You find that all the data comes in different levels of granularity. The transaction data has timestamps (day, hour, minutes, seconds), pricing is stored at the daily level, and revenue data is only reported monthly. What is your next step?
A. Report back to the business owner that the current data model does not support the business question.
B. Interpolate a daily model for revenue from the monthly revenue data.
C. Aggregate all data to the monthly level in order to create a monthly revenue model.
D. Disregard revenue as a driver in the pricing model,and create a daily model based on pricing and transactions only.
Questions 8
Which characteristic applies only to Business Intelligence as opposed to Data Science?
A. Uses only structured data
B. Supports solving "what if" scenarios
C. Uses large data sets
D. Uses predictive modeling techniques
Questions 9
You are using k-means clustering to classify heart patients for a hospital. You have chosen Patient Sex, Height, Weight, Age and Income as measures and have used 3 clusters. When you create a pair-wise plot of the clusters, you notice that there is significant overlap between the clusters. What should you do?
A. Identify additional measures to add to the analysis
B. Remove one of the measures
C. Decrease the number of clusters
D. Increase the number of clusters
Questions 10
Refer to the exhibit.
You are asked to write a report on how specific variables impact your client's sales using a data set
provided to you by the client. The data includes 15 variables that the client views as directly related to
sales, and you are restricted to these variables only.
After a preliminary analysis of the data, the following findings were made:
1.
Multicollinearity is not an issue among the variables
2.
Only three variables--A, B, and C--have significant correlation with sales You build a linear regression
model on the dependent variable of sales with the independent variables of A, B, and C. The results of the
regression are seen in the exhibit.
Which interpretation is supported by the analysis?
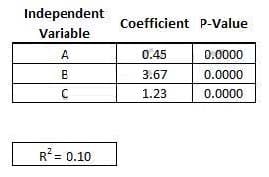
A. Variables A,B,and C are significantly impacting sales,but are not effectively estimating sales
B. Variables A,B,and C are significantly impacting sales and are effectively estimating sales
C. Due to the R2 of 0.10,the model is not valid ?the linear regression should be re-run with all 15 variables forced into the model to increase the R2
D. Due to the R2 of 0.10,the model is not valid ?a different analytical model should be attempted
Questions 11
Refer to the exhibit.
You have plotted the distribution of savings account sizes for your bank. How would you proceed, based
on this distribution?
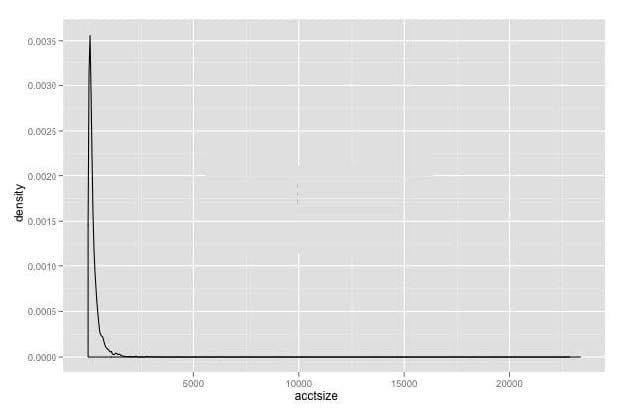
A. The data is extremely skewed. Replot the data on a logarithmic scale to get a better sense of it.
B. The data is extremely skewed,but looks bimodal; replot the data in the range 2,500-10,000 to be sure.
C. The accounts of size greater than 2500 are rare,and probably outliers. Eliminate them from your future analysis.
D. The data is extremely skewed. Split your analysis into two cohorts: accounts less than 2500,and accounts greater than 2500
Questions 12
Refer to the exhibit.
You have created a density plot of purchase amounts from a retail website as shown. What should you do
next?
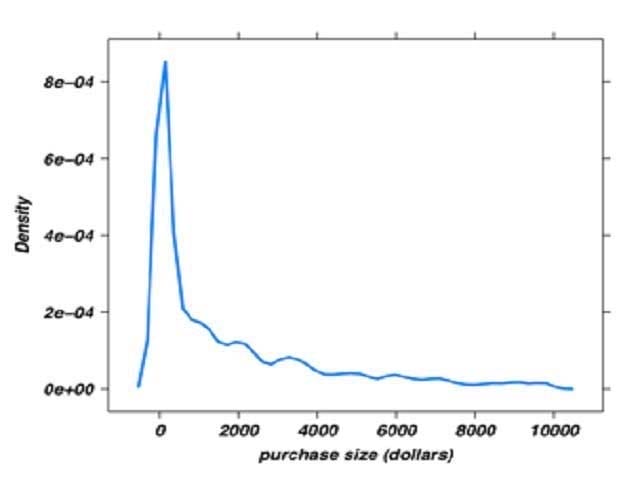
A. Recreate the plot using the barplot() function
B. Use the rug() function to add elements to the plot
C. Recreate the density plot using a log normal distribution of the purchase amount data
D. Reduce the sample size of the purchase amount data used to create the plot
Questions 13
Refer to the exhibit.
You have run a linear regression model against your data, and have plotted true outcome versus predicted
outcome. The R-squared of your model is 0.75. What is your assessment of the model?
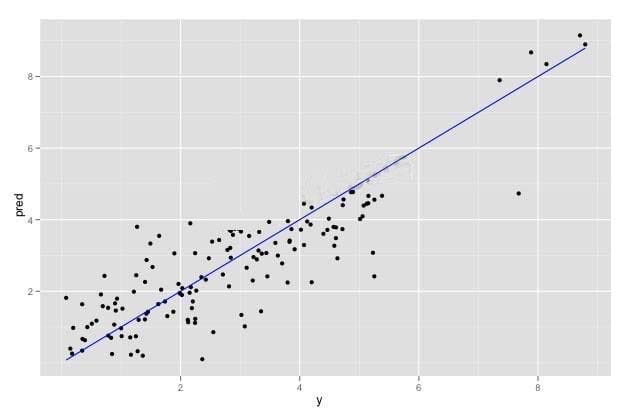
A. The R-squared may be biased upwards by the extreme-valued outcomes. Remove them and refit to get a better idea of the model's quality over typical data.
B. The R-squared is good. The model should perform well.
C. The extreme-valued outliers may negatively affect the model's performance. Remove them to see if the R-squared improves over typical data.
D. The observations seem to come from two different populations,but this model fits them both equally well.
![]()
![]()
Home | About Us | Contact Us | FAQ | Guarantee Policy | Privacy Policy
Any charges made through this site will appear as Global Simulators Limited. All trademarks are the property of their respective owners.
Copyright © 2004-2025 pass2lead.com, All Rights Reserved.