
E20-007 Online Practice Questions and Answers
Questions 4
You have been assigned to do a study of the daily revenue effect of a pricing model of online transactions. You have tested all the theoretical models in the previous model planning stage, and all tests have yielded statistically insignificant results. What is your next step?
A. Report that the results are insignificant, and reevaluate the original business question.
B. Run all the models again against a larger sample, leveraging more historical data.
C. Move forward on the model with the highest significance scores relative to the others.
D. Modify samples used by the models and iterate until a significant result occurs.
Questions 5
In which lifecycle stage are initial hypotheses formed?
A. Discovery
B. Model planning
C. Model building
D. Data preparation
Questions 6
Refer to the exhibit.
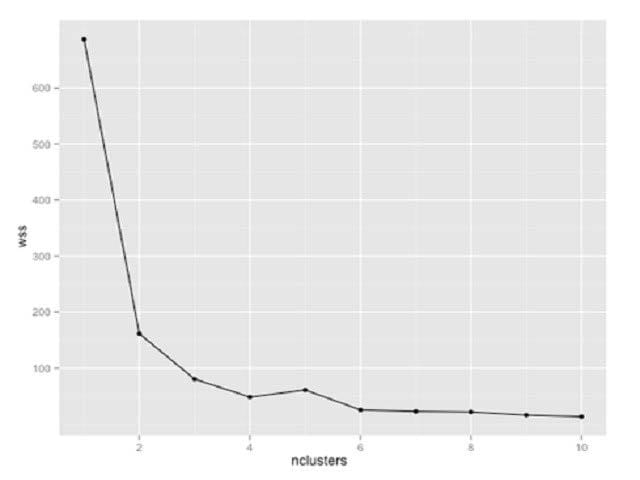
You are using K-means clustering to classify customer behavior for a large retailer. You need to determine the optimum number of customer groups. You plot the within-sum-of- squares (wss) data as shown in the exhibit. How many customer groups should you specify?
A. 2
B. 3
C. 4
D. 8
Questions 7
Since R factors are categorical variables, they are most closely related to which data classification level?
A. nominal
B. ordinal
C. interval
D. ratio
Questions 8
Which data type value is used for the observed response variable in a logistic regression model?
A. Any positive real number
B. Any integer
C. A binary value
D. Any real number
Questions 9
Which word or phrase completes the statement? Mahout is to Hadoop as MADlib is to ____________ .
A. PostgreSQL
B. R
C. Excel
D. SAS
Questions 10
Which characteristic applies only to Business Intelligence as opposed to Data Science?
A. Uses only structured data
B. Supports solving "what if" scenarios
C. Uses large data sets
D. Uses predictive modeling techniques
Questions 11
Which of the following is an example of quasi-structured data?
A. OLAP
B. OLTP
C. Customer record table
D. Clickstream data
Questions 12
You have scored your Na飗e Bayesian Classifier model on "hold out" test data for cross validation. You have determined the way the samples scored and have tabulated them as shown in the exhibit.
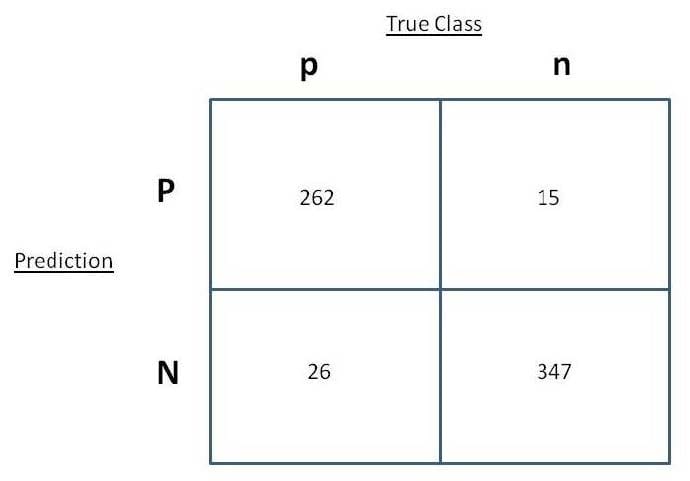
What are the Precision and Recall rates of the model?
A. Precision = 262/277 Recall = 262/288
B. Precision =262/288 Recall = 262/277
C. Precision = 277/262 Recall = 288/262
D. Precision = 288/262 Recall = 277/262
Questions 13
Under which circumstance do you need to implement N-fold cross-validation after creating a regression model?
A. There is not enough data to create a test set.
B. The data is unformatted.
C. There are missing values in the data.
D. There are categorical variables in the model.
![]()
![]()
Home | About Us | Contact Us | FAQ | Guarantee Policy | Privacy Policy
Any charges made through this site will appear as Global Simulators Limited. All trademarks are the property of their respective owners.
Copyright © 2004-2025 pass2lead.com, All Rights Reserved.